
Tabla de contenido
- Qué es el Model Context Protocol
- El problema que resuelve MCP
- Arquitectura MCP: hosts, clients y servers
- Cómo funciona MCP paso a paso
- Servidores MCP populares en 2026
- Cómo instalar un servidor MCP
- MCP en Claude Code
- MCP vs APIs tradicionales
- Seguridad y permisos en MCP
- Preguntas frecuentes sobre MCP
- El protocolo que le quitó la excusa a la IA
Qué es el Model Context Protocol
El Model Context Protocol, conocido como MCP, es un protocolo abierto creado por Anthropic y publicado en noviembre de 2024. Su propósito es uno solo: darle a los modelos de inteligencia artificial una forma estandarizada de conectarse con herramientas externas, fuentes de datos y servicios del mundo real. Antes de MCP, cada integración entre un modelo de IA y una aplicación externa requería su propio conector personalizado. Con MCP, eso cambia radicalmente porque hay un lenguaje común que todos pueden hablar.
La analogía que usa la propia comunidad de MCP es bastante buena: MCP es como el puerto USB-C de los modelos de IA. Antes de que existiera un estándar universal de carga, cada fabricante tenía su propio cable y su propio conector. Conectar un dispositivo de una marca con un cargador de otra era una lotería. MCP hace exactamente eso pero para la IA: define un estándar universal para que cualquier modelo pueda conectarse con cualquier herramienta sin que alguien tenga que escribir adaptadores personalizados para cada combinación posible.
Técnicamente, MCP es un protocolo de código abierto. Cualquiera puede leer la especificación, construir servidores MCP para sus propias aplicaciones y conectarlos con cualquier cliente MCP compatible. Anthropic no solo lo publicó como un estándar sino que en diciembre de 2025 lo donó a la Linux Foundation, que creó la Agentic AI Foundation para administrar su desarrollo futuro. Eso le quita el sabor de "proyecto de una sola empresa" y lo convierte en infraestructura neutral de la industria.
El ecosistema creció a un ritmo que pocos anticipaban. Para principios de 2025, ya había más de 1.000 servidores MCP disponibles según CData Software. Para octubre del mismo año, el registro de PulseMCP listaba más de 5.500 servidores. Empresas como Block, Apollo, Zed, Replit, Codeium y Sourcegraph fueron de los primeros en integrarlo. Hoy, en 2026, casi cualquier herramienta de desarrollo seria tiene o está construyendo su servidor MCP.
Lo que hace especial a MCP no es solo la estandarización, sino el tipo de conexión que permite. No se trata de que un modelo lea documentación sobre cómo usar una API y luego la llame. Se trata de que el modelo descubra dinámicamente qué herramientas están disponibles, entienda qué hace cada una, y las use de forma autónoma para completar tareas complejas. Esa diferencia, entre saber cómo funciona algo y poder usarlo directamente, es lo que hace que MCP sea una pieza fundamental para los agentes de IA.
El problema que resuelve MCP
Para entender por qué MCP importa, hay que entender el problema que existía antes. Los modelos de lenguaje son extraordinariamente capaces dentro de su ventana de contexto, pero están atrapados en una caja. No tienen acceso a internet en tiempo real, no pueden ver tu base de datos, no saben qué hay en tu carpeta de Google Drive y no pueden enviar un mensaje por Slack a menos que alguien les dé acceso explícito. Cada vez que un equipo de desarrollo quería conectar un modelo con una herramienta externa, tenía que construir un integrador personalizado desde cero.
Ese problema tiene un nombre técnico: el problema N x M. Si hay N modelos de IA y M herramientas externas, entonces se necesitan N multiplicado por M integraciones diferentes. Con cinco modelos y veinte herramientas, son cien integraciones. Con diez modelos y cincuenta herramientas, son quinientas. Cada una con su propia lógica de autenticación, su propio manejo de errores, su propio formato de respuesta. Un desperdicio monumental de tiempo de ingeniería que, además, se rompe cada vez que cualquiera de los dos lados actualiza su API.
MCP colapsa ese problema N x M en algo mucho más manejable. Con el protocolo, se necesita una sola implementación por herramienta (el servidor MCP) y una sola implementación por modelo (el cliente MCP). Las integraciones se convierten en N + M en lugar de N x M. Si tienes diez modelos y cincuenta herramientas, son sesenta implementaciones en total, no quinientas. La matemática sola ya justifica la existencia del protocolo.
Pero el problema va más allá de la cantidad de integraciones. Antes de MCP, los modelos de IA dependían de contexto estático: información que alguien copiaba manualmente en el prompt, documentos adjuntos, o datos que la aplicación inyectaba de forma hardcodeada. Eso significa que la IA siempre trabajaba con información potencialmente desactualizada. MCP resuelve eso con acceso dinámico: el modelo puede consultar en tiempo real la base de datos, el sistema de tickets, el CRM o cualquier otra fuente de verdad, y trabajar con datos actuales en lugar de capturas de pantalla del mes pasado.
Hay otro problema que MCP ataca de frente: la portabilidad. Cuando construyes una integración personalizada para conectar, digamos, Claude con tu sistema de base de datos, esa integración es exclusiva para Claude. Si mañana decides cambiar a otro modelo, tienes que reescribir todo. Con MCP, construyes el servidor una vez y cualquier cliente MCP compatible puede usarlo, independientemente del modelo que esté detrás. Eso le da a las empresas una flexibilidad que antes simplemente no existía.
Arquitectura MCP: hosts, clients y servers
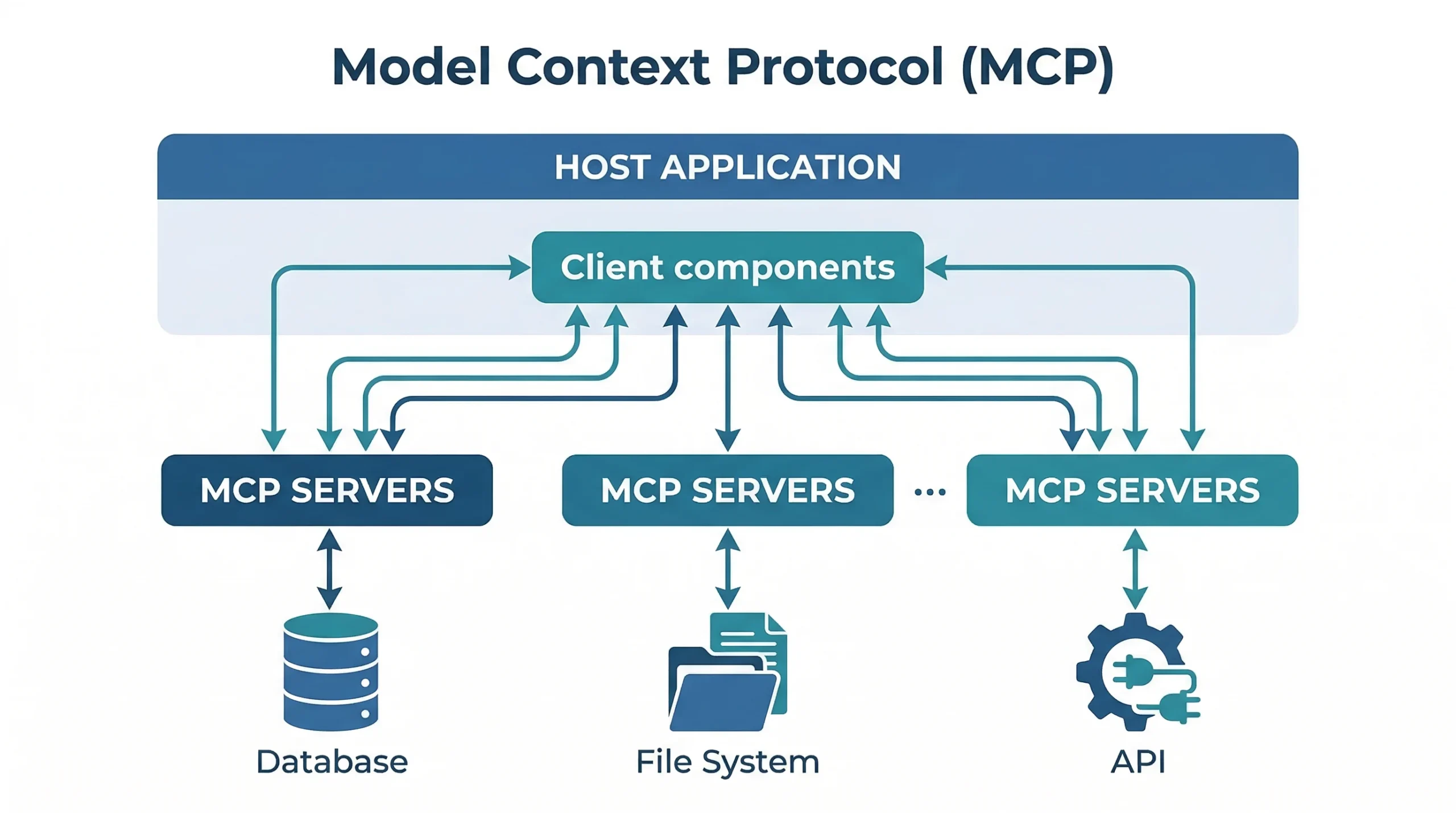
La arquitectura de MCP tiene tres componentes principales: el host, el client y el server. Entender la diferencia entre los tres es fundamental para trabajar con el protocolo, y la confusión entre ellos es la causa número uno de dolores de cabeza cuando alguien está aprendiendo MCP por primera vez. La documentación oficial de MCP los define con bastante claridad, aunque a veces la terminología puede resultar confusa.
 https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-300x167.webp 300w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-1024x572.webp 1024w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-768x429.webp 768w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-1536x857.webp 1536w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-2048x1143.webp 2048w" sizes="auto, (max-width: 2560px) 100vw, 2560px" />
https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-300x167.webp 300w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-1024x572.webp 1024w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-768x429.webp 768w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-1536x857.webp 1536w, https://andresospina.co/wp-content/uploads/2026/03/body-4-architecture-2048x1143.webp 2048w" sizes="auto, (max-width: 2560px) 100vw, 2560px" />{kind=link}
{kind=link}
{kind=link}
{kind=link}
El MCP Host es la aplicación de IA que el usuario final usa directamente. Claude Desktop es un host. Claude Code es un host. VS Code con extensión de IA es un host. Cursor es un host. El host es la capa que coordina todo: gestiona uno o varios clientes MCP, le presenta las capacidades disponibles al modelo de lenguaje, y maneja la interfaz con el usuario. Piénsalo como el orquestador que sabe qué servidores tiene conectados y qué puede hacer con ellos.
El MCP Client es un componente que vive dentro del host. Por cada servidor MCP al que el host se conecta, instancia un cliente MCP dedicado. El cliente es el que habla directamente con el servidor, mantiene la conexión activa, descubre las capacidades disponibles y ejecuta las llamadas a herramientas. La diferencia importante es que el usuario no interactúa con el cliente directamente: el host gestiona los clientes por detrás de escena. Un host puede tener múltiples clientes, uno por cada servidor conectado.
El MCP Server es el programa que expone capacidades al exterior. Un servidor MCP puede ofrecer tres tipos de primitivas: herramientas (tools), recursos (resources) y prompts. Las herramientas son funciones ejecutables, como hacer una query a una base de datos, enviar un correo, o crear un issue en GitHub. Los recursos son fuentes de datos que el modelo puede consultar, como el contenido de archivos o el esquema de una base de datos. Los prompts son plantillas de interacción que el servidor puede sugerirle al modelo para usos específicos. Un servidor puede correr localmente en la misma máquina o de forma remota en la nube.
La comunicación entre cliente y servidor usa dos capas. La capa de datos implementa JSON-RPC 2.0, que es el protocolo estándar para llamadas a procedimientos remotos basado en JSON. Esta capa maneja el ciclo de vida de la conexión, la negociación de capacidades y la ejecución de primitivas. La capa de transporte define cómo viajan físicamente esos mensajes. Hay dos opciones: stdio (entrada y salida estándar, para servidores locales que corren como procesos en la misma máquina) y Streamable HTTP (para servidores remotos que usan HTTP POST con soporte opcional de Server-Sent Events para streaming).
| Componente | Rol | Ejemplos | Transporte |
|---|---|---|---|
| MCP Host | Aplicación de IA que el usuario usa | Claude Desktop, Claude Code, VS Code, Cursor | N/A (orquestador) |
| MCP Client | Conector interno del host hacia servidores | Instanciado automáticamente por el host | Stdio o HTTP |
| MCP Server | Expone herramientas, recursos y prompts | GitHub MCP, Notion MCP, Postgres MCP | Stdio (local) o HTTP (remoto) |
Una distinción operativa importante es entre servidores locales y remotos. Los servidores locales corren como procesos en la misma máquina del usuario y se comunican por stdio. Son más rápidos porque no tienen overhead de red, pero solo sirven a un cliente a la vez. Los servidores remotos corren en infraestructura en la nube y se comunican por HTTP. Pueden servir a miles de clientes simultáneamente, son más fáciles de mantener y actualizar, y no requieren que el usuario instale nada adicional. En 2025, según el análisis de MCP Manager, los servidores remotos crecieron casi 4 veces respecto a mayo, señal de que las empresas grandes están apostando por este modelo de despliegue.
Cómo funciona MCP paso a paso
Entender el flujo de una interacción MCP de principio a fin es lo que separa a alguien que usa MCP de alguien que entiende MCP. El proceso tiene etapas bien definidas que ocurren cada vez que el host establece una conexión con un servidor, y luego cada vez que el modelo decide usar una herramienta. Siguiendo la especificación oficial, así es como funciona en la práctica.
El primer paso es la inicialización. Cuando el host arranca (por ejemplo, cuando abres Claude Code), instancia un cliente MCP por cada servidor que tienes configurado y envía un mensaje initialize. Ese mensaje incluye la versión del protocolo que soporta el cliente, sus capacidades, y metadatos sobre la aplicación. El servidor responde con su propia versión, sus capacidades y sus metadatos. Luego el cliente envía una notificación notifications/initialized para confirmar que el handshake fue exitoso. Todo esto ocurre en menos de un segundo y establece el contrato entre las dos partes sobre qué puede hacer cada quien.
El segundo paso es el descubrimiento de herramientas. El cliente envía una llamada tools/list al servidor, que responde con un array de herramientas disponibles. Cada herramienta tiene un nombre, una descripción en texto natural, y un esquema JSON que describe qué parámetros acepta y de qué tipo son. El host agrega todas las herramientas de todos los servidores conectados en un registro centralizado que el modelo puede consultar. El modelo nunca ve el protocolo directamente: ve la lista de herramientas disponibles como parte de su contexto y puede razonar sobre cuál usar.
El tercer paso es la ejecución de herramientas. Cuando el modelo decide que necesita usar una herramienta (por ejemplo, hacer una query a la base de datos para responder una pregunta), genera una llamada estructurada con el nombre de la herramienta y los argumentos correspondientes. El host intercepta esa llamada, identifica qué cliente MCP debe manejarla, y el cliente envía una llamada tools/call al servidor con el nombre y los argumentos. El servidor ejecuta la acción real (la query SQL, la llamada a la API, la lectura del archivo) y devuelve el resultado. El cliente pasa ese resultado de vuelta al modelo, que lo usa para continuar generando su respuesta.
Un ejemplo concreto ayuda a hacer esto tangible. Imagina que le preguntas a Claude Code: "¿Cuántos issues abiertos tiene este repositorio?" Claude Code tiene el servidor de GitHub MCP configurado. El flujo es: (1) el modelo reconoce que necesita datos de GitHub, (2) identifica la herramienta list_issues del servidor GitHub MCP, (3) genera la llamada con el parámetro state="open", (4) el cliente MCP envía esa llamada al servidor GitHub MCP, (5) el servidor hace la llamada real a la API de GitHub con el token de autenticación configurado, (6) devuelve la lista de issues en formato JSON, (7) el modelo usa esos datos para formular su respuesta. Todo ese flujo ocurre de forma transparente para el usuario.
También existe el mecanismo de notificaciones para cambios en tiempo real. Si el servidor tiene habilitada la capacidad listChanged, puede enviar una notificación notifications/tools/list_changed cuando sus herramientas disponibles cambian. El cliente responde haciendo una nueva llamada tools/list para actualizar su registro. Esto permite que los servidores dinámicos, por ejemplo uno que expone herramientas basadas en los plugins instalados en un sistema, actualicen sus capacidades sin reiniciar la conexión.
Además de herramientas, el flujo para recursos es similar pero usa resources/list y resources/get. Los recursos son útiles para cosas como darle al modelo acceso al esquema de una base de datos, al contenido de archivos de configuración, o a documentación que necesita consultar. La diferencia con las herramientas es que los recursos son datos que el modelo lee, mientras que las herramientas son acciones que el modelo ejecuta.
Todo lo que publico aquí es gratis. Implementarlo contigo tiene precio.
Si algo de lo que leíste te hizo pensar "esto me está pasando", hablemos. Te respondo el mismo día.
Agendar 30 min →Servidores MCP populares en 2026
El ecosistema de servidores MCP en 2026 es enorme. Hay servidores para prácticamente cualquier herramienta que uses en tu trabajo, desde bases de datos hasta plataformas de pagos, pasando por herramientas de diseño y sistemas de gestión de proyectos. Aquí están los que tienen adopción real y casos de uso concretos, no los que suenan bien en papel pero nadie usa.
GitHub MCP
El servidor oficial de GitHub es uno de los más usados del ecosistema. Permite que el modelo gestione repositorios, revise pull requests, cree y cierre issues, inspeccione workflows de GitHub Actions y navegue por el código. Para equipos de desarrollo que trabajan con Claude Code, es prácticamente indispensable porque cierra el ciclo entre escribir código y gestionar el repositorio donde ese código vive. El servidor está mantenido por GitHub y tiene soporte oficial.
Notion MCP
El servidor de Notion conecta al modelo con bases de datos, páginas y bloques del workspace. Permite crear páginas, actualizar registros, buscar contenido y gestionar bases de datos en lenguaje natural. Es especialmente útil para equipos que usan Notion como su sistema de gestión del conocimiento y quieren que la IA pueda leer y escribir en esa base sin que alguien tenga que copiar y pegar información manualmente. Notion tiene servidor oficial disponible para todos sus usuarios.
Supabase MCP
Para equipos que construyen sobre Supabase, el servidor MCP correspondiente permite que el modelo haga queries a bases de datos de desarrollo, explore esquemas, y cree funciones backend sin que el desarrollador tenga que escribir SQL manualmente o adivinar el schema. Para alguien que no es experto en bases de datos, esto es particularmente poderoso porque el modelo puede inferir la estructura y construir las consultas correctas.
Stripe MCP
El servidor de Stripe permite gestionar pagos, suscripciones, webhooks y ciclos de facturación a través del modelo. El caso de uso típico es que un desarrollador pueda pedirle al modelo que consulte el estado de pagos de un cliente, que investigue un webhook fallido, o que genere un reporte de facturación, sin tener que navegar manualmente por el dashboard de Stripe o construir un script ad-hoc. Stripe tiene servidor oficial.
Zapier MCP y Make MCP
Zapier ofrece lo que probablemente es el servidor MCP con mayor alcance del ecosistema: acceso a más de 8.000 aplicaciones y 40.000 acciones. Eso significa que con un solo servidor, el modelo puede disparar workflows en prácticamente cualquier herramienta de negocio, desde enviar correos hasta actualizar registros en CRM, pasando por crear entradas en hojas de cálculo o publicar en redes sociales. Está disponible en todos los planes de Zapier, incluyendo el gratuito. Make tiene una oferta similar con énfasis en automatizaciones más complejas.
Context7 MCP
Context7 resuelve uno de los problemas más frustrantes del desarrollo con IA: los modelos a veces generan código usando versiones antiguas de librerías porque su entrenamiento tiene un corte de fecha. Context7 proporciona documentación actualizada y ejemplos de código específicos de la versión actual de las herramientas más populares. Thoughtworks lo incluyó en su Technology Radar de noviembre de 2025 como una herramienta para explorar, y funciona especialmente bien con Claude Code y Cursor.
Otros servidores relevantes
El ecosistema incluye servidores para Linear (gestión de proyectos de ingeniería), Figma (diseño y exportación de código), HubSpot (CRM), Slack, Google Drive, PostgreSQL, Playwright (testing de interfaces), y decenas más. DataCamp publicó una lista de los 15 servidores remotos más relevantes de 2026 que incluye muchas de estas opciones con detalles de configuración y casos de uso.
| Servidor MCP | Categoría | Casos de uso principales | Tipo |
|---|---|---|---|
| GitHub MCP | Desarrollo | Repos, issues, pull requests, Actions | Remoto |
| Notion MCP | Productividad | Bases de datos, páginas, búsqueda | Remoto |
| Supabase MCP | Base de datos | Queries, schema, funciones backend | Local/Remoto |
| Stripe MCP | Pagos | Pagos, suscripciones, facturación | Remoto |
| Zapier MCP | Automatización | 8.000+ apps, 40.000+ acciones | Remoto |
| Context7 MCP | Desarrollo | Documentación actualizada de librerías | Remoto |
| Figma MCP | Diseño | Frame-to-code, design systems | Remoto |
| Linear MCP | Proyectos | Sprints, tickets, gestión de ingeniería | Remoto |
Cómo instalar un servidor MCP
Instalar un servidor MCP es más sencillo de lo que parece. Hay dos caminos principales: hacerlo en Claude Desktop (para uso conversacional) o en Claude Code (para flujos de desarrollo). Los pasos difieren ligeramente, pero la lógica es la misma: configurar un archivo JSON que le dice al host qué servidores debe arrancar y cómo conectarse a ellos.
Instalación en Claude Desktop
Para instalar un servidor MCP en Claude Desktop, primero necesitas tener Node.js instalado en tu máquina (la mayoría de servidores lo requieren). Luego el proceso es así. Abre Claude Desktop, ve a Configuración, luego a la pestaña de Desarrollador, y haz clic en "Editar configuración". Eso abre (o crea) un archivo llamado claude_desktop_config.json. En macOS está en ~/Library/Application Support/Claude/, en Windows en %APPDATA%\Claude\.
Dentro de ese archivo JSON, agregas una sección mcpServers con la configuración de cada servidor. Para el servidor de GitHub, por ejemplo, se vería así:
{
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_TOKEN": "tu_token_personal_aqui"
}
}
}
}Guardas el archivo, reinicias Claude Desktop, y listo. El host va a arrancar automáticamente el servidor de GitHub cuando inicie, y las herramientas de GitHub van a aparecer disponibles en tus conversaciones. Para agregar múltiples servidores, simplemente añades más entradas dentro de mcpServers, cada una con su propio nombre como clave.
Instalación en Claude Code
En Claude Code, el proceso es aún más directo porque hay comandos CLI específicos para gestionar servidores MCP. No tienes que editar archivos JSON manualmente. El comando principal es claude mcp add con el tipo de transporte, el nombre del servidor y la URL o comando correspondiente.
Para agregar un servidor HTTP remoto (como el de Notion), el comando es:
claude mcp add --transport http notion https://mcp.notion.com/mcpPara un servidor local basado en stdio (como el de GitHub con npx), el comando es:
claude mcp add github -- npx -y @modelcontextprotocol/server-githubClaude Code maneja tres alcances de instalación. El alcance local (por defecto) instala el servidor solo para el proyecto actual en tu directorio raíz. El alcance de proyecto agrega la configuración a un archivo mcp.json dentro del repositorio, de modo que cualquier persona que clone el proyecto tenga acceso al mismo servidor sin configuración adicional. El alcance de usuario instala el servidor globalmente en tu máquina para todos los proyectos. Para especificar el alcance, usas la flag --scope project o --scope user.
Para verificar qué servidores tienes configurados, usas claude mcp list. Para ver los detalles de un servidor específico, claude mcp get nombre-del-servidor. Para eliminar uno, claude mcp remove nombre-del-servidor. Una vez configurado, puedes verificar que las herramientas están disponibles usando el comando /mcp dentro de una sesión de Claude Code.
Las variables de entorno con tokens y credenciales se manejan mejor con export antes de arrancar Claude Code, o configurándolas directamente en el archivo de configuración del servidor dentro del campo env. Nunca pongas tokens en el código que va a tu repositorio: usa variables de entorno del sistema o archivos .env que estén en tu .gitignore.
MCP en Claude Code
Claude Code y MCP son una combinación que amplifica las capacidades de ambas cosas. Claude Code ya es extraordinariamente poderoso como agente de desarrollo autónomo. Cuando le agregas servidores MCP, se convierte en algo diferente: un agente que puede leer tu código, escribirlo, ejecutar tests, ver los resultados, consultar la documentación de la librería que estás usando, revisar los issues relacionados en GitHub, actualizar el ticket de Linear, y notificar al equipo en Slack, todo en la misma sesión y sin que tengas que intervenir en cada paso.
El flujo de trabajo que se vuelve posible con MCP en Claude Code es cualitativamente diferente al que tenías antes. Un ejemplo concreto: le dices a Claude Code "implementa el endpoint para crear usuarios con validación de email, crea los tests unitarios, y crea un issue en GitHub documentando la API". Con el servidor de GitHub MCP configurado, Claude Code puede hacer esas tres cosas en secuencia sin que tú tengas que abrir el browser o cambiar de herramienta. Escribe el código, escribe los tests, y crea el issue con la documentación generada automáticamente.
Para el caso de uso de marketing y crecimiento, que es donde Claude Code para marketing brilla especialmente, MCP abre posibilidades concretas. Con el servidor de HubSpot MCP puedes pedirle a Claude Code que analice el pipeline de ventas de los últimos 30 días y genere un reporte. Con el servidor de Google Analytics puedes pedirle que identifique las páginas con mayor tasa de rebote y sugiera mejoras. Con el servidor de Ahrefs puedes pedirle que analice las keywords de la competencia y priorice oportunidades de contenido. Todo eso sin salir de la terminal.
Claude Code también puede funcionar él mismo como un servidor MCP. Eso significa que otras aplicaciones o agentes pueden conectarse a Claude Code a través del protocolo y usar sus capacidades de desarrollo de código como una herramienta más dentro de su flujo. Es un caso de uso más avanzado, pero abre posibilidades interesantes para pipelines de automatización donde Claude Code es el componente de generación de código en un sistema más grande.
Una cosa práctica que vale mencionar: cuando tienes muchos servidores MCP configurados, la lista de herramientas disponibles puede volverse larga. Claude Code maneja esto bien porque el modelo puede razonar sobre qué herramienta es apropiada para cada tarea, pero hay un límite práctico. Instala solo los servidores que uses regularmente en cada proyecto, y aprovecha el alcance de proyecto para mantener las configuraciones organizadas por contexto.
Para los agentes de IA más complejos, MCP en Claude Code es el pegante que une múltiples capacidades en un flujo coherente. En lugar de tener que orquestar manualmente las llamadas a diferentes APIs, el agente puede descubrir dinámicamente qué herramientas están disponibles y encadenarlas según la tarea. Ese nivel de autonomía es lo que hace que los agentes modernos sean cualitativamente distintos a los chatbots de hace dos años.
MCP vs APIs tradicionales
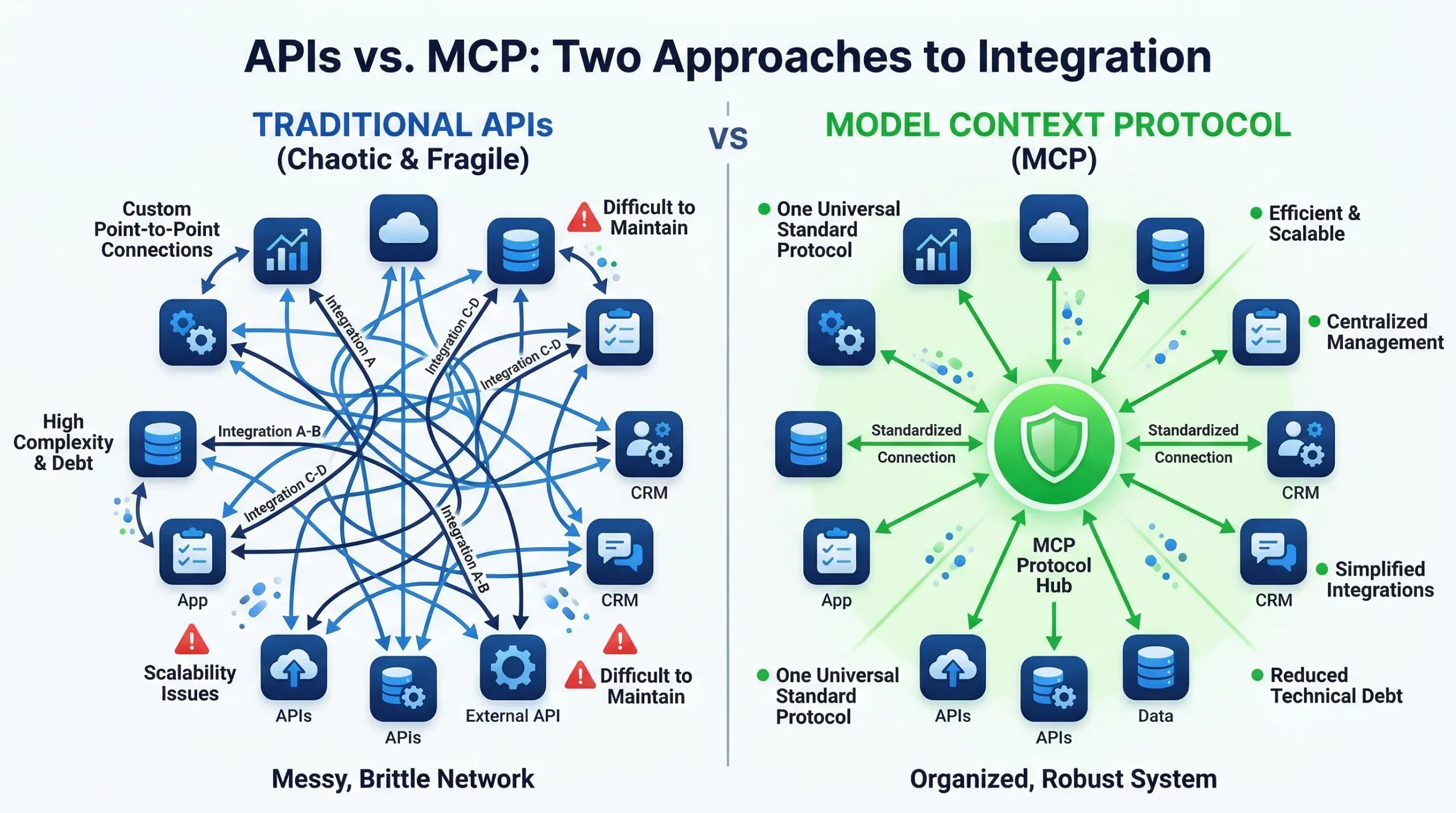
La comparación entre MCP y las APIs tradicionales es una que aparece todo el tiempo, y a veces se presenta como si fueran competidores directos. No lo son. MCP es una capa encima de las APIs, no un reemplazo para ellas. Los servidores MCP hablan con APIs por detrás: el servidor de GitHub MCP hace llamadas a la API REST de GitHub, el servidor de Stripe MCP hace llamadas a la API de Stripe. Lo que cambia es quién hace esas llamadas y cómo se descubren y usan las capacidades disponibles.
 https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-300x167.webp 300w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-1024x572.webp 1024w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-768x429.webp 768w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-1536x857.webp 1536w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-2048x1143.webp 2048w" sizes="auto, (max-width: 2560px) 100vw, 2560px" />
https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-300x167.webp 300w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-1024x572.webp 1024w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-768x429.webp 768w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-1536x857.webp 1536w, https://andresospina.co/wp-content/uploads/2026/03/body-4-comparison-2048x1143.webp 2048w" sizes="auto, (max-width: 2560px) 100vw, 2560px" />{kind=link}
{kind=link}
{kind=link}
{kind=link}
La diferencia fundamental es el consumidor. Las APIs tradicionales están diseñadas para ser consumidas por código escrito por humanos. Un desarrollador lee la documentación, entiende los endpoints, escribe el código de integración, maneja los errores, gestiona la autenticación. Todo eso requiere intervención humana activa. MCP está diseñado para ser consumido por modelos de IA. El modelo lee la descripción de las herramientas disponibles (que está en lenguaje natural más un esquema JSON), decide cuál usar según el contexto, genera los parámetros correctos y procesa la respuesta. No hay código de integración escrito por humanos en el medio.
Desde el punto de vista de la interfaz, las APIs tradicionales son estáticas: tienes que saber de antemano qué endpoints existen y qué hacen. MCP es dinámico: el cliente descubre las herramientas disponibles en tiempo de ejecución mediante tools/list. Eso significa que si el servidor agrega nuevas herramientas, el modelo las puede usar de inmediato sin que nadie actualice el código del cliente. Esa flexibilidad es especialmente valiosa en entornos donde las capacidades cambian frecuentemente.
En términos de comunicación, las APIs REST son principalmente request-response: el cliente hace una petición y espera una respuesta. MCP soporta comunicación bidireccional: el servidor puede enviar notificaciones al cliente (como tools/list_changed), el servidor puede pedirle al cliente que solicite una completion del modelo (sampling), y puede solicitar confirmación del usuario antes de ejecutar acciones sensibles (elicitation). Esa bidireccionalidad es lo que hace a MCP adecuado para flujos agenticos complejos.
| Aspecto | API tradicional | MCP |
|---|---|---|
| Consumidor primario | Código escrito por humanos | Modelos de IA |
| Descubrimiento | Documentación estática | Dinámico en tiempo de ejecución |
| Comunicación | Request-response unidireccional | Bidireccional con notificaciones |
| Integración | Una integración por modelo/herramienta | Un servidor sirve a todos los modelos |
| Portabilidad | Integración atada a un modelo específico | Cualquier cliente MCP puede conectarse |
| Actualización | Requiere actualizar el código cliente | El cliente descubre cambios automáticamente |
| Autenticación | Hardcodeada en el código | Gestionada por el servidor MCP |
La pregunta práctica es cuándo usar cada cosa. Si estás construyendo una integración específica entre dos sistemas de software con requisitos muy particulares, una API directa puede ser la opción más eficiente. Si estás construyendo capacidades que quieres que estén disponibles para agentes de IA de forma autónoma, MCP es la elección correcta. Y si ya tienes una API existente que quieres hacer accesible para agentes, construir un servidor MCP que la envuelva es generalmente la forma más rápida de lograrlo.
Hay casos donde MCP agrega latencia sin beneficio proporcional. Si tienes un caso de uso simple y repetitivo donde siempre llamas el mismo endpoint con los mismos parámetros, el overhead de MCP no tiene sentido. Pero para workflows agenticos donde el modelo necesita decidir dinámicamente qué herramientas usar, MCP justifica completamente el costo adicional de configuración.
Seguridad y permisos en MCP
La seguridad de MCP es uno de los temas que más preguntas genera, y con razón. Cuando le das a un modelo de IA la capacidad de ejecutar herramientas reales en el mundo real, las consecuencias de una acción incorrecta o maliciosa son muy concretas: datos borrados, transacciones no autorizadas, acceso a información sensible. Según la Encuesta de Estado de MCP de Zuplo, el 50% de los desarrolladores que trabajan con MCP citan seguridad y control de acceso como su principal desafío, y el 38% dicen que las preocupaciones de seguridad están bloqueando activamente su adopción más amplia.
El primer riesgo que hay que entender es el problema del "confused deputy" (el intermediario confundido). Cuando un servidor MCP ejecuta una acción, idealmente debería hacerlo con los permisos del usuario, no con los permisos propios del servidor. En la práctica, muchas implementaciones no hacen esa distinción correctamente: el servidor tiene un token de API con permisos amplios, y cualquier acción que ejecute usa esos permisos completos, independientemente de qué permisos tenga el usuario que hizo la solicitud. Si la implementación del servidor no es cuidadosa, un usuario puede terminar accediendo a recursos que no debería poder ver, simplemente porque el servidor tiene acceso a ellos.
El segundo riesgo importante es la inyección de prompts a través de herramientas. Imagina que tienes un servidor MCP que lee emails y otro que puede enviar mensajes de Slack. Un atacante podría enviar un email con instrucciones maliciosas embebidas en el cuerpo del mensaje, diseñadas para que el modelo las interprete como comandos. Si el modelo lee ese email a través del servidor MCP y luego interpreta el contenido malicioso como instrucciones, podría ejecutar acciones no autorizadas usando las otras herramientas disponibles. Este tipo de ataque, llamado prompt injection indirecto, es particularmente difícil de detectar porque el contenido malicioso llega a través de una fuente aparentemente legítima.
El tercer riesgo es el de herramientas maliciosas (tool injection). No todos los servidores MCP disponibles en internet son confiables. Un servidor con un nombre inocente podría tener descripciones de herramientas diseñadas para confundir al modelo sobre lo que hacen, o podría actualizarse después de la instalación para cambiar el comportamiento de sus herramientas. Un 25% de los servidores MCP disponibles públicamente no tienen ningún tipo de autenticación, según los datos de la encuesta de Zuplo. Usar servidores de fuentes no verificadas es un riesgo de seguridad real.
Además de estos tres, Red Hat identifica riesgos de cadena de suministro (dependencias comprometidas en el código del servidor), inyección de comandos en servidores locales que ejecutan procesos del sistema operativo sin sanitizar los inputs, y abuso del mecanismo de sampling donde un servidor malicioso puede pedirle al modelo que complete tareas dañinas.
Las buenas prácticas para mitigar estos riesgos son concretas. Primero, usa solo servidores MCP de fuentes verificadas: servidores oficiales de los propios proveedores de las herramientas, o servidores de repositorios bien mantenidos con revisiones activas. Segundo, aplica el principio de mínimo privilegio: configura los tokens de API con los permisos mínimos necesarios, no con acceso completo. Un servidor de GitHub que solo necesita leer repositorios no necesita permisos de escritura. Tercero, fija las versiones de los servidores que usas para evitar que actualizaciones automáticas cambien su comportamiento sin tu conocimiento. Cuarto, habilita la confirmación del usuario para acciones sensibles, especialmente las que modifican o eliminan datos. Quinto, mantén logs de las acciones ejecutadas por los servidores MCP para poder auditar comportamientos anómalos.
MCP tiene soporte nativo para OAuth 2.1 en servidores remotos con transporte HTTP, lo que permite manejar autenticación de forma estandarizada. El estándar también define el principio de mínimo privilegio como una expectativa explícita: los clientes deben solicitar solo los scopes (permisos) necesarios para su operación. Sin embargo, que el estándar lo exija y que las implementaciones lo cumplan son dos cosas diferentes, por lo que la revisión manual de la configuración sigue siendo necesaria.
Preguntas frecuentes sobre MCP
¿MCP es solo para Claude o funciona con otros modelos?
MCP funciona con cualquier modelo que tenga un cliente MCP implementado. Aunque Anthropic lo creó y Claude tiene soporte nativo, OpenAI y Google también anunciaron soporte para el protocolo en 2025. En la práctica, hay clientes MCP para VS Code, Cursor, Windsurf, Zed, Replit y otros entornos de desarrollo que pueden usarse con múltiples modelos. La naturaleza abierta del protocolo es precisamente lo que permite esta interoperabilidad: cualquier empresa puede implementar un cliente MCP en su producto y conectarse con los servidores existentes del ecosistema.
¿Necesito saber programar para usar MCP?
Para usar servidores MCP existentes en Claude Desktop o Claude Code, no necesitas saber programar más allá de editar un archivo JSON o ejecutar comandos básicos en la terminal. Para la mayoría de servidores populares hay documentación clara con los comandos exactos que necesitas. Donde sí se requieren conocimientos de programación es para construir tu propio servidor MCP personalizado, lo que implica escribir código en Node.js, Python u otro lenguaje compatible. Pero para la mayoría de casos de uso cotidianos, instalar y configurar servidores existentes está al alcance de cualquiera con disposición para seguir instrucciones.
¿Cuál es la diferencia entre un servidor MCP local y uno remoto?
Un servidor MCP local corre como un proceso en tu propia máquina y se comunica con el cliente a través de stdin/stdout. Es más rápido porque no hay overhead de red, pero requiere que instales el servidor en cada máquina donde lo uses. Un servidor MCP remoto corre en infraestructura en la nube y se comunica por HTTP. Solo necesitas la URL para conectarte, sin instalar nada localmente. Los servidores remotos son más fáciles de mantener y escalar, y permiten que varios usuarios compartan la misma instancia. La tendencia en el ecosistema va hacia servidores remotos, especialmente para herramientas empresariales.
¿Cómo sé qué herramientas están disponibles en un servidor MCP?
Puedes ver las herramientas disponibles de varias formas. En Claude Code, el comando claude mcp get nombre-del-servidor muestra los detalles del servidor, y el comando /mcp dentro de una sesión activa muestra el estado de los servidores conectados y sus herramientas. En Claude Desktop, las herramientas disponibles aparecen como un ícono de herramientas en la interfaz de chat. La mayoría de servidores también tienen su propia documentación que lista todas las herramientas disponibles con sus parámetros. Adicionalmente, puedes preguntarle directamente al modelo qué herramientas tiene disponibles y listará las que puede usar.
¿MCP reemplaza los function calls o tool use de los modelos?
No exactamente. Los function calls son el mecanismo interno por el cual los modelos expresan su intención de usar una herramienta, generando una llamada estructurada con nombre y parámetros. MCP es la capa de transporte y protocolo que conecta esa intención con la ejecución real. El host recibe el function call del modelo, lo enruta al servidor MCP correcto a través del cliente, y devuelve el resultado. MCP y function calls trabajan juntos: los function calls son el lenguaje que usa el modelo, MCP es la infraestructura que hace que esas llamadas lleguen a donde deben llegar y que las respuestas vuelvan correctamente.
El protocolo que le quitó la excusa a la IA
Durante años, la respuesta estándar a "¿por qué la IA no puede hacer X?" fue alguna variante de "los modelos están aislados, no tienen acceso a datos en tiempo real, necesitan integraciones personalizadas". Eso era cierto, y era un freno real para la adopción de IA en flujos de trabajo complejos. Cada empresa que quería conectar un modelo con sus herramientas internas tenía que invertir semanas de ingeniería en construir adaptadores que inevitablemente quedaban desactualizados cuando alguna de las dos partes cambiaba.
MCP no resuelve todos los problemas de la IA aplicada. Los modelos siguen cometiendo errores, siguen necesitando supervisión humana en tareas de alto impacto, y la seguridad sigue siendo una preocupación legítima que requiere atención activa. Pero MCP sí resuelve el problema de la conectividad de forma sistemática, y eso tiene un efecto multiplicador en todo lo demás. Un modelo que puede acceder a datos actualizados, ejecutar herramientas reales y encadenar acciones en múltiples sistemas es cualitativamente más útil que uno que no puede.
Lo que hace que el ecosistema de 2026 sea diferente al de 2024 es que ya no hay que convencer a nadie de que MCP es el camino. OpenAI, Google, Microsoft y docenas de plataformas SaaS ya tienen servidores o clientes MCP. La pregunta dejó de ser "¿deberíamos adoptar MCP?" y pasó a ser "¿qué servidores MCP necesitamos para nuestro flujo de trabajo específico?" Ese cambio de pregunta es la mejor señal de que el protocolo logró lo que se propuso.
Para quienes trabajan con Claude Code en el día a día, MCP es la diferencia entre tener un asistente de código muy bueno y tener un agente que puede completar tareas de principio a fin sin que tengas que actuar como intermediario entre herramientas. Esa diferencia, entre asistir y actuar, es donde está el valor real. Y MCP es la infraestructura que lo hace posible.
Si no has configurado ningún servidor MCP todavía, empieza por uno solo: el que más tiempo te ahorra en tu flujo de trabajo actual. Si pasas mucho tiempo consultando GitHub, instala el GitHub MCP. Si vives en Notion, instala el Notion MCP. El punto de entrada no importa tanto como el hábito de empezar a pensar en términos de herramientas conectadas. Ese cambio de mentalidad es el que separa a quienes usan la IA como un buscador mejorado de quienes la usan como lo que realmente puede ser.
© 2026 Andres Ospina
